
AI & Infrastructure: The New DevOps Frontier
In January 2026 I gave a talk to students at UM6P/1337 in Morocco on the convergence of AI and infrastructure. The premise was simple: the DevOps engineer of 2015 and the platform engineer of 2026 share a title but inhabit different worlds. The former managed containers and CI pipelines; the latter must also manage GPU clusters, model registries, prompt versioning, and inference costs that can dwarf the rest of the infrastructure budget combined.
This article is an expanded version of that talk. It covers MLOps, AIOps, LLMs as infrastructure, the platforms that support AI workloads, and the evolving skillset that modern engineers need to bridge both worlds.
The Convergence
Traditional DevOps brought us CI/CD pipelines, container orchestration, infrastructure as code, and observability practices. These remain foundational. But AI has introduced new layers of complexity that demand new approaches.
On the AI side, we have Large Language Models, machine learning pipelines, training infrastructure, and inference services. These systems don’t fit neatly into traditional DevOps patterns.
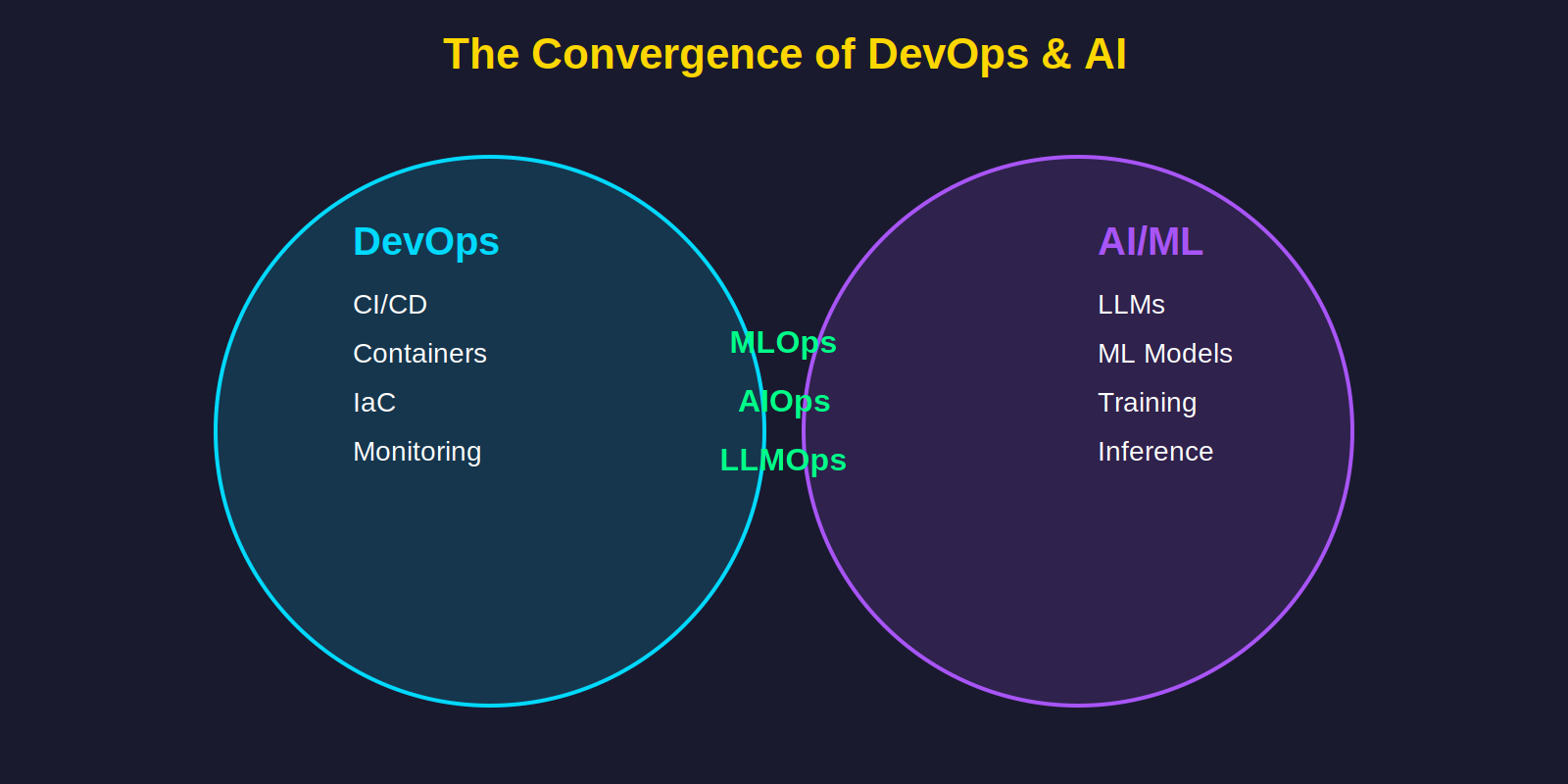
The convergence creates three new disciplines:
- MLOps: Applying DevOps principles to machine learning systems
- AIOps: Using AI to improve IT operations
- LLMOps: Operating LLM infrastructure at production scale
Each represents a different direction of integration, but all require engineers who can bridge both worlds.
MLOps — DevOps for the Probabilistic World
MLOps extends DevOps principles to machine learning, but the challenges are fundamentally different. In traditional software, the same code produces the same behaviour. In ML systems, the same code with different data produces different behaviour. This is the core complexity that MLOps addresses.
DevOps vs MLOps
| Aspect | DevOps | MLOps |
|---|---|---|
| Versioning | Code (Git) | Code + Data + Models |
| Pipelines | CI/CD | CT/CD (Continuous Training) |
| Testing | Unit & Integration | Model & Data validation |
| Monitoring | Application metrics | Model drift detection |
| Rollback | Previous code version | Model + data dependencies |
The shift from deterministic to probabilistic systems changes everything. Testing becomes statistical rather than binary. Monitoring must detect gradual degradation, not just failures. Rollback requires understanding which data produced which model.
The MLOps Pipeline
A mature MLOps pipeline consists of five stages:
Data Stage
# Data versioning with DVC
import dvc.api
# Track data changes alongside code
data_path = dvc.api.get_url(
path='data/training/dataset.csv',
repo='[email protected]:org/ml-project.git',
rev='v1.2.0'
)
# Data quality checks
from great_expectations.core import ExpectationSuite
suite = ExpectationSuite("training_data")
suite.add_expectation(
expect_column_values_to_not_be_null(column="target")
)
suite.add_expectation(
expect_column_values_to_be_between(
column="feature_1", min_value=0, max_value=100
)
)
Training Stage
# Experiment tracking with MLflow
import mlflow
with mlflow.start_run():
mlflow.log_params({
"learning_rate": 0.001,
"batch_size": 32,
"epochs": 100
})
model = train_model(X_train, y_train)
mlflow.log_metrics({
"accuracy": accuracy,
"f1_score": f1,
"auc_roc": auc
})
mlflow.sklearn.log_model(model, "model")
Validation Stage
# Model validation against baseline
def validate_model(new_model, baseline_model, test_data):
new_metrics = evaluate(new_model, test_data)
baseline_metrics = evaluate(baseline_model, test_data)
# Statistical significance test
improvement = new_metrics['accuracy'] - baseline_metrics['accuracy']
p_value = statistical_test(new_model, baseline_model, test_data)
return {
'passes': improvement > 0.01 and p_value < 0.05,
'improvement': improvement,
'p_value': p_value
}
Deployment Stage
# Model registry and deployment
from mlflow.tracking import MlflowClient
client = MlflowClient()
# Register model
model_uri = f"runs:/{run_id}/model"
mv = client.create_model_version(
name="fraud_detection",
source=model_uri,
run_id=run_id
)
# Promote to production after validation
client.transition_model_version_stage(
name="fraud_detection",
version=mv.version,
stage="Production"
)
Monitoring Stage
# Drift detection
from evidently.metrics import DataDriftPreset
from evidently.report import Report
def check_drift(reference_data, production_data):
report = Report(metrics=[DataDriftPreset()])
report.run(
reference_data=reference_data,
current_data=production_data
)
drift_detected = report.as_dict()['metrics'][0]['result']['dataset_drift']
if drift_detected:
trigger_retraining_pipeline()
return drift_detected
The MLOps Technology Stack
The tooling landscape for MLOps has matured significantly:
Experiment Tracking & Model Registry
- MLflow: Open source, comprehensive, good starting point
- Weights & Biases: Excellent visualization, collaborative features
- Neptune: Strong experiment management focus
Feature Stores
- Feast: Open source, Kubernetes-native
- Tecton: Enterprise features, real-time serving
- Hopsworks: Integrated with data platforms
Orchestration
- Kubeflow Pipelines: Kubernetes-native ML workflows
- Airflow: General purpose, widely adopted
- Prefect/Dagster: Modern alternatives with better DX
Model Serving
- KServe: Serverless inference on Kubernetes
- Seldon Core: Kubernetes-native, feature rich
- Triton Inference Server: Multi-framework, GPU optimized
- BentoML: Framework for packaging and serving
MLOps Maturity Model
Most organisations fall into one of four maturity levels:
Level 0 - Manual Process
- Data scientists work in notebooks
- Manual model export and deployment
- No versioning or reproducibility
- This describes 70-80% of organisations
Level 1 - Pipeline Automation
- Automated training pipelines
- Experiment tracking in place
- Basic model versioning
- Manual deployment decisions
Level 2 - CI/CD for ML
- Automated testing for data and models
- Continuous training triggers
- Model registry with approval workflows
- Feature store adoption
Level 3 - Full MLOps
- Automated retraining based on drift
- A/B testing and gradual rollouts
- Complete observability
- Self-healing pipelines
The goal is incremental improvement, not a leap to Level 3.
AIOps — When the Machine Watches the Machine
AIOps inverts the relationship—instead of applying DevOps to AI, we apply AI to DevOps. The premise is simple: modern systems generate more data than humans can process. AI can help.
The Scale Problem
A typical enterprise environment generates:
- Millions of log entries per hour
- Thousands of metric time series
- Hundreds of alerts per day
Traditional rule-based monitoring cannot keep pace. Static thresholds generate false positives. Alert fatigue causes teams to miss real issues.
AIOps applies machine learning to:
- Detect anomalies automatically
- Correlate related alerts
- Predict failures before they occur
- Automate incident response
ML-Based Anomaly Detection
The fundamental improvement over static thresholds:
# Static threshold (traditional)
def static_alert(cpu_usage):
return cpu_usage > 80 # Always alerts at 80%
# ML-based dynamic baseline
from sklearn.ensemble import IsolationForest
import numpy as np
class DynamicBaseline:
def __init__(self, window_size=168): # 1 week of hourly data
self.model = IsolationForest(contamination=0.01)
self.history = []
self.window_size = window_size
def update(self, value, hour_of_week):
# Include temporal features
features = [value, hour_of_week, np.sin(2*np.pi*hour_of_week/168)]
self.history.append(features)
if len(self.history) > self.window_size:
self.history.pop(0)
self.model.fit(self.history)
def is_anomaly(self, value, hour_of_week):
features = [[value, hour_of_week, np.sin(2*np.pi*hour_of_week/168)]]
return self.model.predict(features)[0] == -1
The key insight: a CPU spike at Monday 9 AM during batch processing is normal. The same spike at Sunday 3 AM is not. Static thresholds cannot distinguish these cases.
Self-Healing Infrastructure
The ultimate goal of AIOps is autonomous remediation:
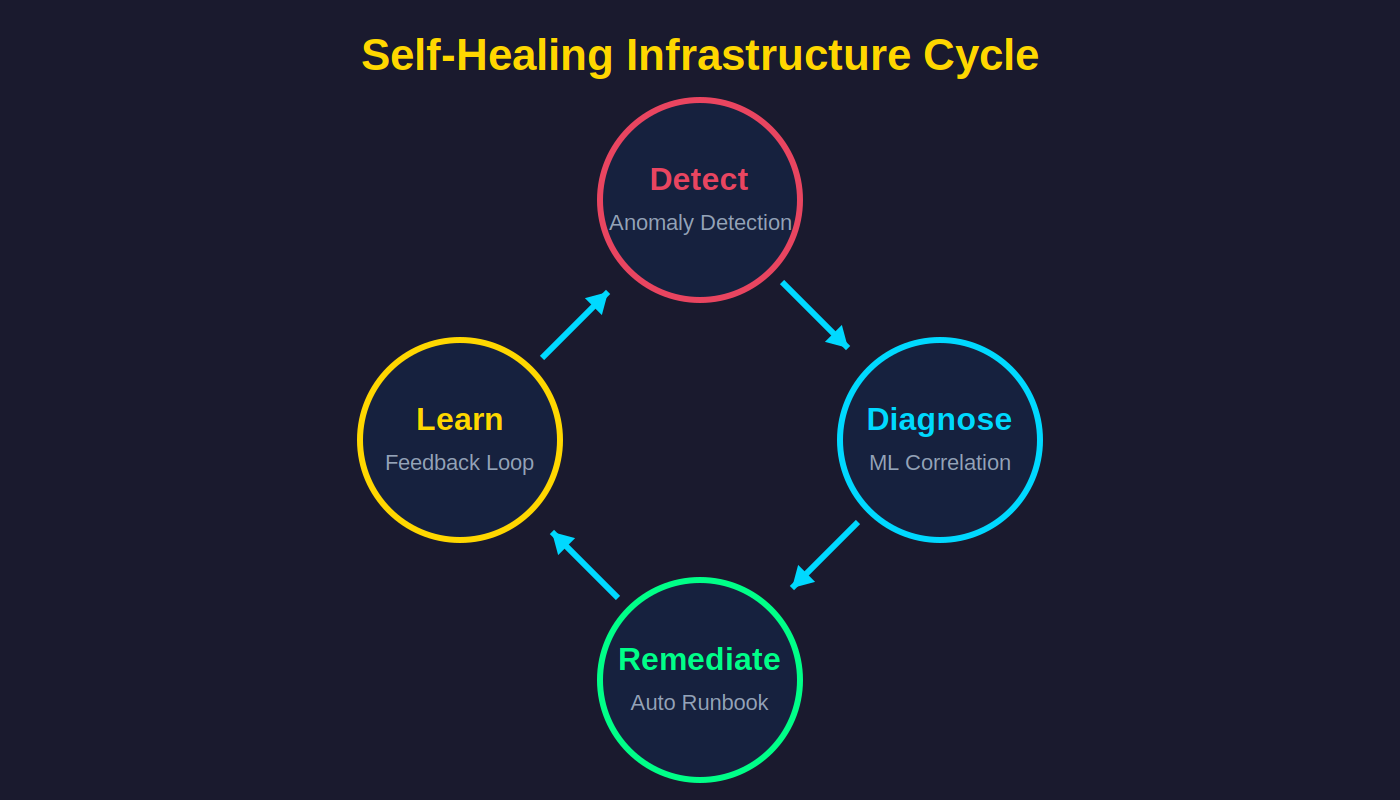
# Example: Kubernetes-based self-healing with custom controller
apiVersion: aiops.io/v1
kind: RemediationPolicy
metadata:
name: memory-pressure-remediation
spec:
trigger:
type: Anomaly
metric: container_memory_usage_bytes
model: isolation_forest
sensitivity: 0.95
diagnosis:
correlations:
- metric: container_restarts
- metric: http_error_rate
- logs: "OutOfMemoryError"
actions:
- type: ScaleUp
condition: "correlation.http_error_rate > 0.8"
target:
deployment: api-server
replicas: "+2"
- type: Restart
condition: "correlation.container_restarts > 3"
target:
pod: "selector:app=api-server"
feedback:
successMetric: http_error_rate
successThreshold: 0.01
learningEnabled: true
The cycle: Detect (anomaly detection) → Diagnose (correlation analysis) → Remediate (automated runbook) → Learn (feedback loop).
Intelligent Alert Correlation
Converting thousands of alerts into actionable insights:
class AlertCorrelator:
def __init__(self, topology_graph, time_window=300):
self.topology = topology_graph
self.time_window = time_window
self.alert_buffer = []
def process_alert(self, alert):
self.alert_buffer.append(alert)
self.cleanup_old_alerts()
# Group alerts by time proximity
time_groups = self.group_by_time(self.alert_buffer)
# Correlate by topology
for group in time_groups:
correlated = self.correlate_by_topology(group)
# Find root cause candidates
root_causes = self.find_root_causes(correlated)
# Score by business impact
scored = self.score_impact(root_causes)
yield Incident(
alerts=correlated,
probable_causes=scored[:3],
suggested_actions=self.get_runbooks(scored[0])
)
def correlate_by_topology(self, alerts):
# Use graph algorithms to find related services
clusters = []
for alert in alerts:
service = alert.source
neighbors = self.topology.neighbors(service, depth=2)
related = [a for a in alerts if a.source in neighbors]
clusters.append(set(related + [alert]))
# Merge overlapping clusters
return self.merge_clusters(clusters)
The funnel: 10,000 raw alerts → 1,000 after noise reduction → 50 correlated incidents → 10 prioritized issues → 5 actionable items with suggested remediations.
LLMs as Infrastructure — The API That Returns Intelligence
Large Language Models have transitioned from research curiosities to critical infrastructure components. This shift demands that we treat them with the same operational rigor as databases or message queues.
The Evolution of API Value
2005: Google Maps API → Returns location data
2010: Twitter API → Returns social data
2015: Stripe API → Handles payments
2020: Twilio API → Enables communications
2024+: LLM APIs → Returns intelligence
Previous APIs returned data or performed actions. LLM APIs return reasoning. This is a fundamental shift in what an API can provide.
LLM Serving Challenges
LLM serving differs from traditional API serving:
| Aspect | Traditional API | LLM API |
|---|---|---|
| Response time | 10-100ms | 1-30 seconds |
| Memory per request | MBs | 10s-100s GBs |
| Compute | CPU-bound | GPU-bound |
| Cost per request | $0.00001 | $0.01-1.00 |
Optimisation techniques that enable production-scale serving:
# Performance comparison (requests per second on single A100)
optimizations = {
"naive": 10, # Basic implementation
"continuous_batching": 50, # 5x improvement
"paged_attention": 150, # 15x improvement (vLLM)
"quantization_int8": 250, # 25x improvement
"quantization_int4": 300, # 30x improvement
}
Continuous Batching: Process multiple requests together, maximizing GPU utilization.
Paged Attention (vLLM): Efficiently manage GPU memory for the KV cache using virtual memory concepts.
Quantization: Reduce precision from FP16 to INT8 or INT4, trading minimal quality loss for significant speedup.
# vLLM deployment example
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-3-70B-Instruct",
tensor_parallel_size=4, # Distribute across 4 GPUs
quantization="awq", # 4-bit quantization
gpu_memory_utilization=0.9
)
sampling_params = SamplingParams(
temperature=0.7,
max_tokens=1024,
top_p=0.95
)
# Handles batching automatically
outputs = llm.generate(prompts, sampling_params)
The AI Gateway Pattern
A new architectural pattern for managing LLM traffic:
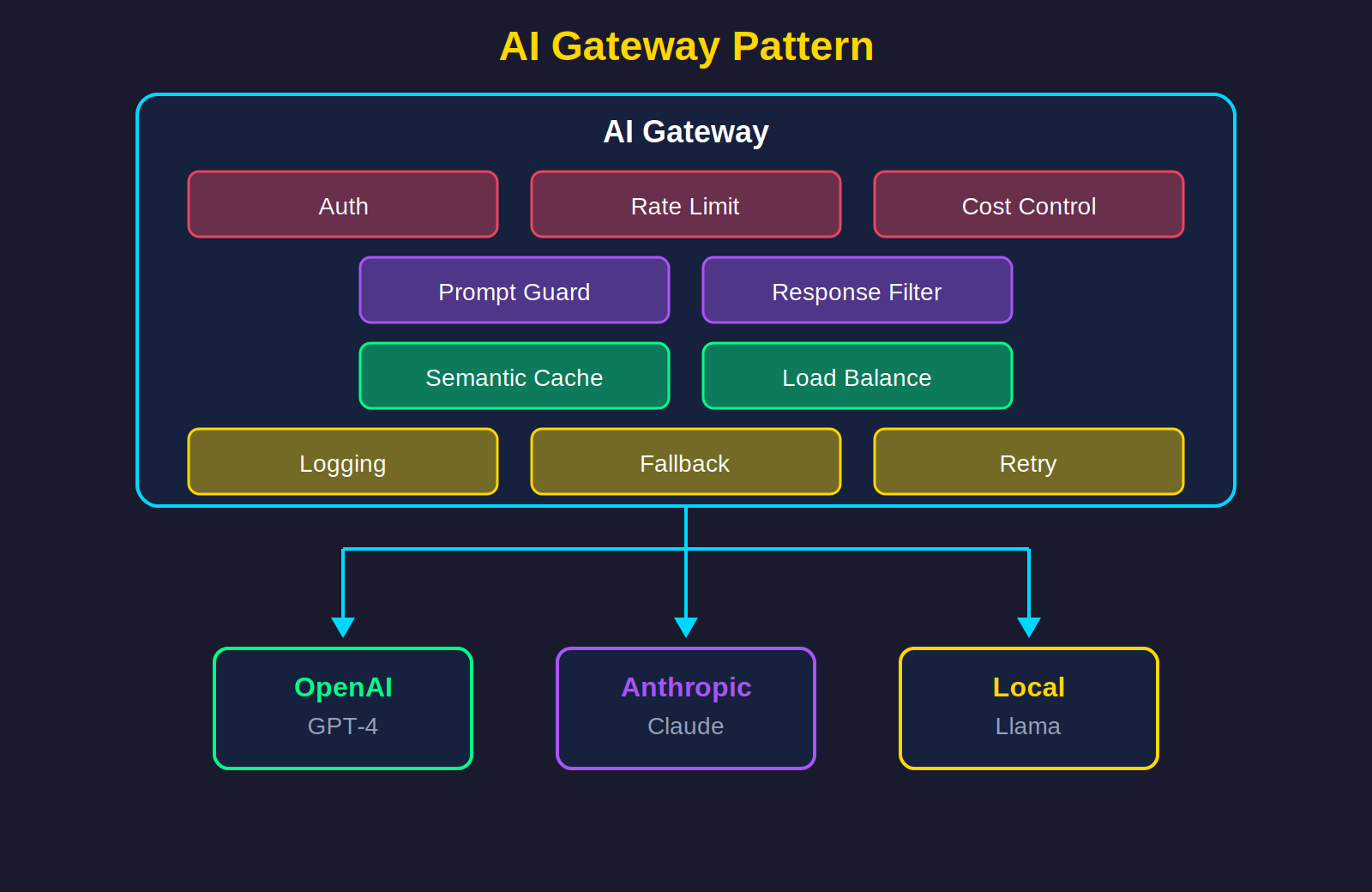
Key capabilities beyond traditional API gateways:
Semantic Caching: “What is the capital of France?” and “France’s capital city?” should hit the same cache entry.
from sentence_transformers import SentenceTransformer
import numpy as np
class SemanticCache:
def __init__(self, similarity_threshold=0.95):
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
self.cache = {} # embedding -> response
self.threshold = similarity_threshold
def get(self, query):
query_embedding = self.encoder.encode(query)
for cached_embedding, response in self.cache.items():
similarity = np.dot(query_embedding, cached_embedding)
if similarity > self.threshold:
return response
return None
def set(self, query, response):
embedding = tuple(self.encoder.encode(query))
self.cache[embedding] = response
Prompt Injection Protection:
def detect_prompt_injection(user_input):
dangerous_patterns = [
r"ignore (all )?(previous|prior|above) instructions",
r"disregard (the )?(system|initial) prompt",
r"you are now",
r"new instruction:",
r"```system",
]
for pattern in dangerous_patterns:
if re.search(pattern, user_input, re.IGNORECASE):
return True
# ML-based detection for sophisticated attacks
injection_score = injection_classifier.predict_proba([user_input])[0][1]
return injection_score > 0.8
Model Routing for cost optimisation:
class ModelRouter:
def __init__(self):
self.complexity_classifier = load_classifier()
self.models = {
"simple": ("gpt-3.5-turbo", 0.002), # $/1K tokens
"medium": ("claude-3-haiku", 0.003),
"complex": ("gpt-4", 0.06)
}
def route(self, prompt):
complexity = self.complexity_classifier.predict([prompt])[0]
model, cost = self.models[complexity]
return model
# 40-60% cost savings by routing simple queries to cheaper models
Prompts as Code
Treating prompts with the same rigor as application code:
# prompts/customer_support/v2.1.yaml
metadata:
name: customer_support_agent
version: "2.1"
author: "platform-team"
created: "2026-01-15"
model:
provider: anthropic
name: claude-3-5-sonnet
temperature: 0.3
max_tokens: 1024
system_prompt: |
You are a helpful customer support agent for TechCorp.
Guidelines:
- Be concise and professional
- If you don't know the answer, say so
- Never make up information about products
- For billing issues, always offer to escalate
Available actions:
- lookup_order(order_id)
- check_inventory(product_id)
- create_ticket(category, description)
user_prompt_template: |
Customer: {customer_name}
Membership: {membership_tier}
Previous interactions: {interaction_count}
Query: {user_message}
tests:
- input:
user_message: "Where is my order #12345?"
expected_contains:
- "lookup_order"
expected_not_contains:
- "I don't have access"
- input:
user_message: "Your product is terrible"
expected_tone: "empathetic"
expected_not_contains:
- "I agree"
Prompt CI/CD pipeline:
# .github/workflows/prompt-ci.yaml
name: Prompt CI/CD
on:
push:
paths:
- 'prompts/**'
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run prompt tests
run: |
python scripts/test_prompts.py prompts/
- name: Evaluate quality metrics
run: |
python scripts/evaluate_prompts.py \
--prompts prompts/ \
--min-relevancy 0.8 \
--min-faithfulness 0.9
- name: Deploy to staging
if: github.ref == 'refs/heads/main'
run: |
python scripts/deploy_prompts.py \
--env staging \
--prompts prompts/
Infrastructure for AI — GPUs, Clusters, and the Cost of Compute
Building infrastructure to support AI workloads requires understanding their unique characteristics: GPU-intensive computation, large memory footprints, and specialized orchestration needs.
Kubernetes for AI Workloads
# GPU-enabled Kubernetes deployment for model training
apiVersion: kubeflow.org/v1
kind: PyTorchJob
metadata:
name: distributed-training
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
template:
spec:
containers:
- name: pytorch
image: training-image:v1.0
resources:
limits:
nvidia.com/gpu: 8
env:
- name: NCCL_DEBUG
value: "INFO"
Worker:
replicas: 3
template:
spec:
containers:
- name: pytorch
image: training-image:v1.0
resources:
limits:
nvidia.com/gpu: 8
nodeSelector:
accelerator: nvidia-h100
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
GPU Sharing Strategies
GPUs are expensive ($10-30K per card). Maximizing utilization is critical.
MIG (Multi-Instance GPU): Physically partition an A100/H100 into up to 7 isolated instances.
# MIG configuration for inference workloads
apiVersion: v1
kind: ConfigMap
metadata:
name: mig-config
data:
config.yaml: |
version: v1
mig-configs:
all-balanced:
- devices: all
mig-enabled: true
mig-devices:
"3g.40gb": 2 # Two 3-GPU slices with 40GB each
Time-Slicing: Share GPU across pods with context switching.
# Time-slicing configuration
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config
data:
any: |-
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4 # Allow 4 pods to share each GPU
MPS (Multi-Process Service): CUDA-level sharing for concurrent kernel execution.
ML Platform Reference Architecture
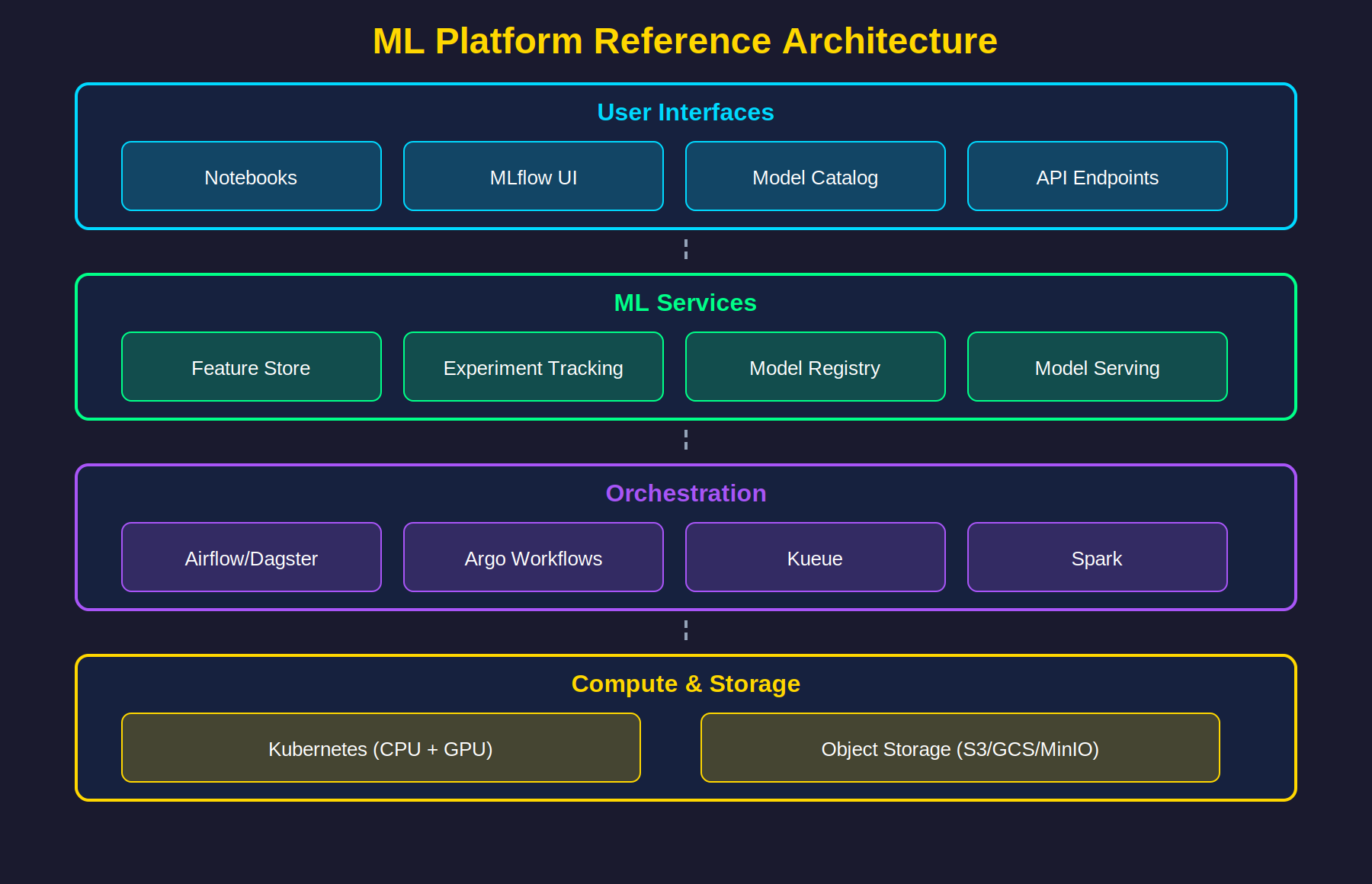
Cost Optimisation
AI infrastructure costs are dominated by GPU compute:
| Component | Typical % of Budget |
|---|---|
| GPU Compute | 60-70% |
| Storage | 15-20% |
| Networking/Egress | 5-10% |
| Other (CPU, memory) | 5-10% |
Optimisation strategies:
Spot Instances for Training
# Training with automatic checkpointing for spot instances
import signal
def checkpoint_handler(signum, frame):
save_checkpoint(model, optimizer, epoch)
sys.exit(0)
signal.signal(signal.SIGTERM, checkpoint_handler)
# Resume from checkpoint if exists
if checkpoint_exists():
model, optimizer, start_epoch = load_checkpoint()
else:
start_epoch = 0
for epoch in range(start_epoch, total_epochs):
train_epoch(model, data)
save_checkpoint(model, optimizer, epoch) # Regular checkpoints
Idle Detection and Scale-to-Zero
# KNative service with scale-to-zero
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: inference-service
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/min-scale: "0"
autoscaling.knative.dev/max-scale: "10"
autoscaling.knative.dev/scale-down-delay: "5m"
spec:
containers:
- image: inference:v1
resources:
limits:
nvidia.com/gpu: 1
Workload Placement Strategies
Train in Cloud, Serve On-Prem: Use cloud GPUs for burst training, deploy models on-premises for data sovereignty and predictable inference costs.
Multi-Cloud Resilience: Use ONNX for model portability across providers.
# Export to ONNX for portability
import torch.onnx
torch.onnx.export(
model,
dummy_input,
"model.onnx",
opset_version=17,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)
Edge AI: Deploy quantized models on edge devices for low-latency inference.
The Evolving Role — What Engineers Need Now
The DevOps engineer of 2015 needed shell scripting, CI/CD, containers, cloud services, and monitoring. The platform engineer of 2026 needs all of that plus:
- ML/AI Literacy: Understanding how models work, their failure modes, and operational requirements
- GPU Infrastructure: Managing GPU clusters, understanding memory hierarchies, optimizing utilization
- LLM Operations: Deploying and managing LLM services, prompt management, cost control
- AI Tool Orchestration: Building pipelines that incorporate AI components
This is not about becoming a data scientist. It’s about understanding AI systems well enough to operate them reliably.
AI-Assisted DevOps
The tools we use are also becoming AI-powered:
Production Ready
- Code completion (GitHub Copilot, Cursor)
- Log analysis and summarization
- Documentation generation
- Code review assistance
Emerging
- Infrastructure as Code generation from natural language
- Incident diagnosis from symptoms
- Test generation from code
- Security vulnerability detection
Future
- Autonomous debugging
- Self-healing systems with minimal human intervention
- Predictive capacity planning
- Automatic performance optimisation
Natural Language to Infrastructure
Human: "Deploy a PostgreSQL database with 3 replicas for high
availability, daily backups retained for 30 days,
accessible only from the backend namespace"
AI generates:
├── terraform/
│ └── database.tf
├── kubernetes/
│ ├── statefulset.yaml
│ ├── service.yaml
│ ├── networkpolicy.yaml
│ └── backup-cronjob.yaml
└── README.md
The workflow becomes: describe intent → AI generates code → human reviews and refines → human tests and deploys. This is augmentation, not replacement.
Closing Reflection
When I finished the UM6P/1337 talk, a student asked me whether platform engineers would eventually be replaced by the AI systems they were building. It is a fair question. My answer was that the engineers who treat AI as a black box — who deploy models the way they once deployed containers, without understanding what is inside — will indeed become redundant. But the engineers who learn to bridge both worlds, who understand why a model drifts and how a GPU memory hierarchy constrains serving latency, will be more valuable than ever. The tooling is getting more powerful, but the problems are getting harder at the same rate. That is not a threat; it is an invitation.
MLOps is the new DevOps. AIOps augments rather than replaces the operator. LLMs are infrastructure components that demand the same rigour as databases. GPU costs dominate budgets and optimisation is a core competency. And the role of the platform engineer is evolving — not shrinking, but expanding — into territory that requires both systems thinking and AI literacy. The convergence is not optional. The only question is whether you engage with it deliberately or have it imposed on you.
AI & Infrastructure: The New DevOps Frontier
An exploration of how artificial intelligence and infrastructure operations are converging.
Achraf SOLTANI — January 24, 2026