
Attention Through the Lens of Numerical Linear Algebra
From the database analogy to randomised approximation — a mathematical reading of the attention mechanism and the numerical methods that now sit underneath every modern Transformer.
I. Motivation
The attention mechanism introduced by Vaswani et al. in 2017 is now the computational core of every frontier language model. It is also, structurally, a kernelised database lookup expressed entirely in dense linear algebra — which is why it is so well suited to GPU hardware, and why it breaks, eventually, on the quadratic cost of self-attending over long sequences.
Two recent preprints by Michel Serret and collaborators at the Paul Scherrer Institute — an introductory tutorial for applied mathematicians, and a full survey of approximation methods through the lens of numerical linear algebra — clarify what Transformers actually compute and where randomised numerical methods intervene. This article distils the mathematical thread that runs through both.
II. Tokens, Embeddings, and the Input Matrix
A Transformer does not consume text. It consumes a matrix.
Given a vocabulary $T = (T_i)_{1 \leq i \leq N_T}$, a piece of text is first tokenised into a sequence of indices in $\{1, \ldots, N_T\}$. A trained embedding matrix $E \in \mathbb{R}^{N_T \times d}$ then sends each token index $i$ to the $i$-th row vector $E_i \in \mathbb{R}^d$. The input to the model is the matrix
$$ X \in \mathbb{R}^{N \times d} $$whose rows are the $d$-dimensional embeddings of the $N$ tokens in the input sequence. The constant $d$ — often called the hidden dimension — is preserved, layer after layer, throughout the network; for reference, Llama 3 70B uses $d = 8192$ with a vocabulary of $\sim 128$k tokens, Gemma 3 27B uses $d = 5376$ with $\sim 262$k tokens.
III. Attention as a Kernelised Database
The attention mechanism is best read as a soft database lookup. Classical key–value lookup returns the value $v$ whose key $k$ equals the query $q$. Attention relaxes equality to similarity: it returns a linear combination of all values, weighted by how close each key is to the query.
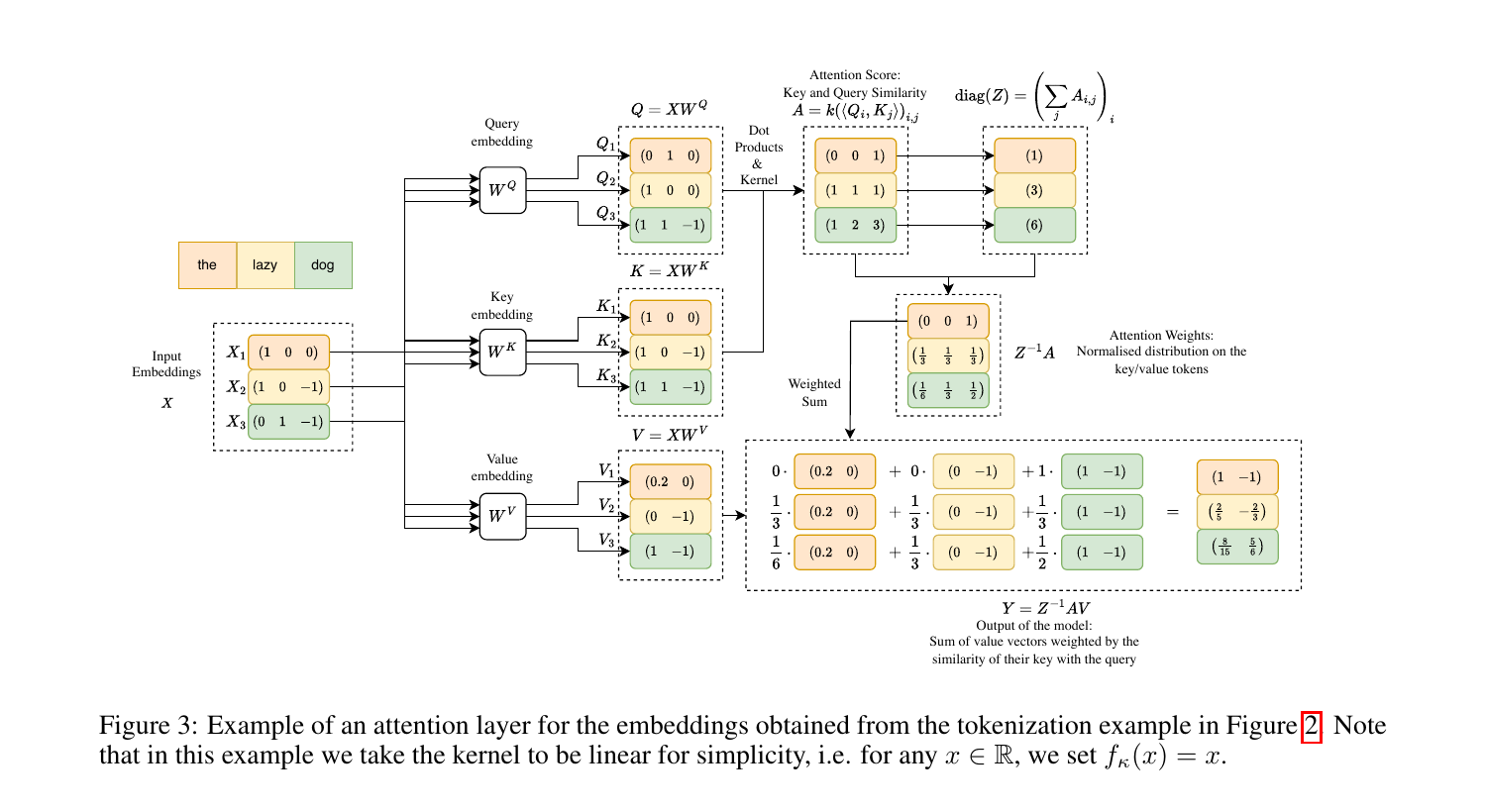
Formally, let $X^Q \in \mathbb{R}^{N_Q \times d}$, $X^K, X^V \in \mathbb{R}^{N_{KV} \times d}$ be input blocks, and let $W^Q, W^K \in \mathbb{R}^{d \times d_{QK}}$, $W^V \in \mathbb{R}^{d \times d_V}$ be learned projection matrices. The query, key and value matrices are
$$ Q = X^Q W^Q, \qquad K = X^K W^K, \qquad V = X^V W^V. $$A symmetric similarity kernel $\kappa: \mathbb{R}^{d_{QK}} \times \mathbb{R}^{d_{QK}} \to \mathbb{R}$ defines the attention score matrix
$$ A_{ij} = \kappa\bigl(Q[i,:],\, K[j,:]\bigr), \qquad A \in \mathbb{R}^{N_Q \times N_{KV}}. $$The matrix $A$ is normalised row-wise by the diagonal matrix $Z = \operatorname{diag}(A \mathbf{1})$, and the final output is
$$ Y = Z^{-1} A V \in \mathbb{R}^{N_Q \times d_V}. $$The original Transformer uses the scaled exponential kernel
$$ \kappa_{\exp}(v, w) = \exp\!\left(\frac{\langle v, w \rangle}{\sqrt{d_{QK}}}\right), $$in which case $Z^{-1} A$ is exactly the row-wise softmax of $QK^\top / \sqrt{d_{QK}}$. The scaling $\sqrt{d_{QK}}$ is not cosmetic: if the entries of $Q$ and $K$ have unit variance, $\langle Q[i,:], K[j,:]\rangle$ has variance $d_{QK}$, and without rescaling the softmax saturates.
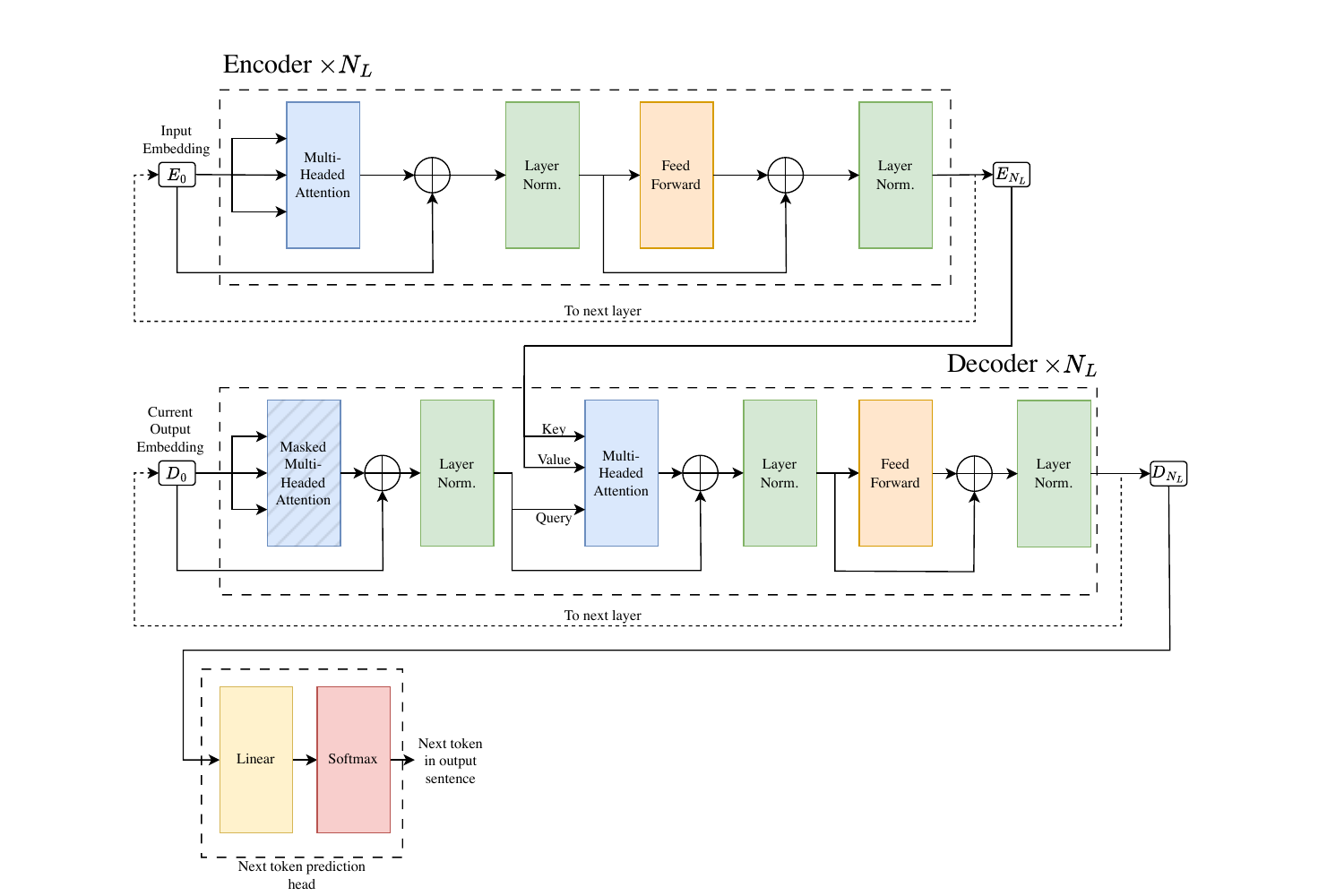
IV. Multi-Headed Attention
One attention layer captures one mode of similarity. To capture several — syntactic, semantic, positional — the computation is replicated in parallel across $N_{\text{heads}}$ heads, each with its own projection matrices $W_h^Q, W_h^K, W_h^V$. The per-head output $Y_h \in \mathbb{R}^{N_Q \times d_{\text{head}}}$ is concatenated column-wise, then projected through an output matrix $W^O$:
$$ Y = \operatorname{concat}_{\text{col}}(Y_1, \ldots, Y_{N_{\text{heads}}}) \, W^O. $$Dimensions are typically chosen so that $N_{\text{heads}} \cdot d_{\text{head}} = d$, making the per-layer parameter count comparable to a single dense matmul.
The full Transformer layer composes this multi-head attention with layer normalisation, a position-wise feed-forward sublayer, and residual connections — a pattern that admits a pre-norm or post-norm variant, with pre-norm now standard in models such as Gemma 3 and Llama 3 because it stabilises gradient flow in deep stacks.
V. The Quadratic Bottleneck
Every attention layer costs $\mathcal{O}(N_Q N_{KV}(d_{QK} + d_V))$ operations. In self-attention, where $N_Q = N_{KV} = N$, this is $\mathcal{O}(N^2 d)$ — quadratic in context length. For a $100$k-token context this is two orders of magnitude more expensive than the feed-forward sublayer that follows.
A partial remedy, at inference time, is KV caching. In autoregressive generation, each new token adds one row to $Q$, $K$, $V$; since previous rows are unchanged, the key and value blocks are accumulated once and reused. This reduces the cost of emitting $N_{\text{tokens}}$ tokens from $\mathcal{O}(N_{\text{tokens}}^3 d)$ to $\mathcal{O}(N_{\text{tokens}}^2 d)$, at the price of $2 N_L N_{\text{heads}} d$ floats of cache per token. For long contexts this cache dominates GPU memory — and so the battle for efficient Transformers becomes, increasingly, a battle over the shape and size of $K$ and $V$.
VI. Sharing the Cache: GQA, MQA, and Latent Attention
Three architectural variants attack the KV footprint directly.
Multi-Query Attention (MQA) replaces the $N_{\text{heads}}$ distinct KV heads by a single shared pair $(K, V)$ used by all query heads. Cache size drops by a factor of $N_{\text{heads}}$, at the cost of some representational capacity.
Grouped Query Attention (GQA) interpolates between MHA and MQA: query heads are partitioned into $N_{\text{groups}}$ groups, each sharing one KV pair. Llama 3 70B uses 64 query heads and 8 KV heads; Gemma 3 27B uses 32 and 16. Empirically, GQA matches MHA quality while cutting KV memory by a factor of $N_{\text{heads}} / N_{\text{groups}}$.
Multi-Head Latent Attention (MLA), introduced in DeepSeek V2, goes further. Rather than sharing fixed KV heads, it factorises the KV projections through a shared low-rank latent subspace of dimension $d_L \ll d$:
$$ W^{\mathbf{K}} = W^L W^{\mathbf{LK}}, \qquad W^{\mathbf{V}} = W^L W^{\mathbf{LV}}, $$so that the per-token cache reduces to a single latent vector $L = X W^L \in \mathbb{R}^{d_L}$, shared across all heads. The head-specific matrices $W^{LK}_h, W^{LV}_h$ can be absorbed into the query and output projections via associativity, yielding
$$ Q_h K_h^\top = L_Q \underbrace{W_h^{L_Q Q} W_h^{LK\,\top}}_{W_h^{LQK} \in \mathbb{R}^{d_{L_Q} \times d_L}} L^\top, $$so the cached tensor has size $\mathcal{O}(N d_L)$ instead of $\mathcal{O}(N \, N_{\text{heads}} \, d_{\text{head}})$. Concretely, DeepSeek V2 has 128 heads of per-head dimension 128 and caches a single $d_L = 512$ latent vector per token, against Llama 3’s 8 KV heads × 128 = 1024 floats per token and an equivalent full-MHA cost of 128 × 128 = 16384 floats per token.
VII. Approximating the Attention Matrix
MLA and GQA reduce the KV footprint, but the operator itself is still the full $N \times N$ softmax. To break the quadratic wall one has to approximate the attention matrix $\overline{A} = Z^{-1} A$ directly.
Empirically, attention matrices from trained Transformers are highly non-uniform: a handful of heavy hitters per row account for most of the mass, and some heads develop attention sinks — columns of persistently large weight acting as no-op targets (Xiao et al., 2024). This sparsity is the opening numerical methods exploit.
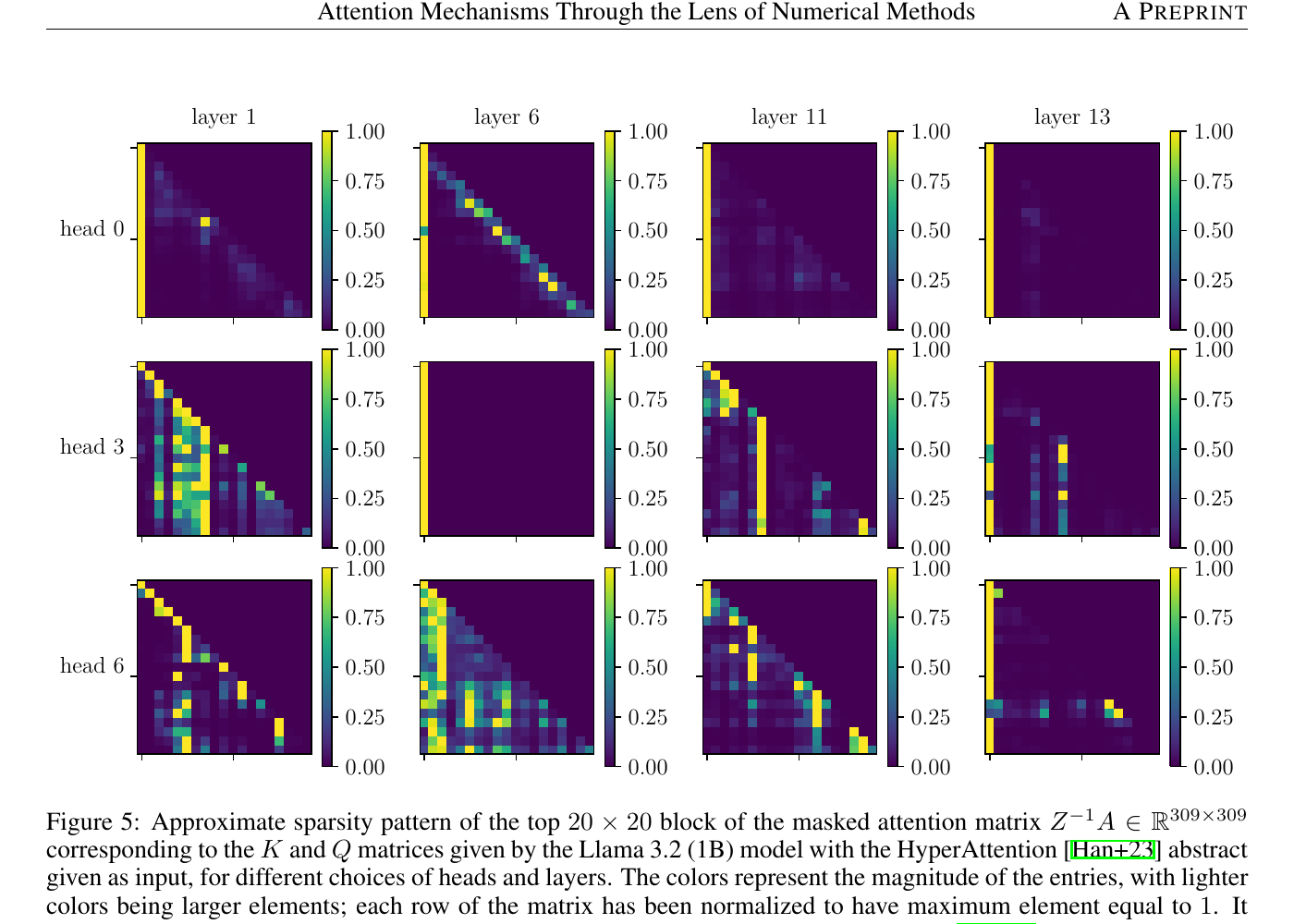
Paper 2 organises the zoo of fast-attention methods into a taxonomy of two trunks — methods that approximate the standard self-attention operator, and methods that replace it with an alternative formulation.
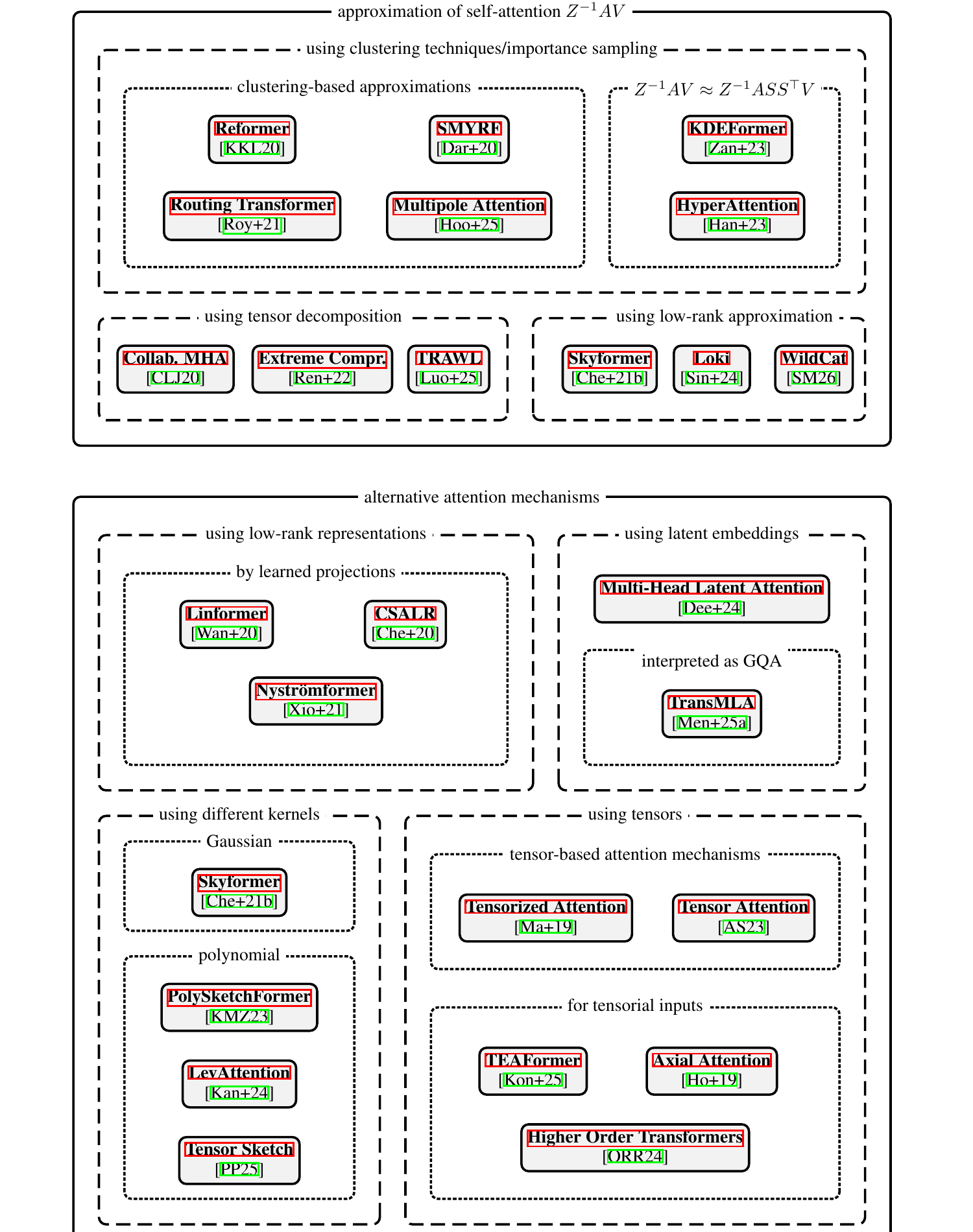
Clustering and locality-sensitive hashing. If queries and keys can be partitioned into clusters of similar vectors, each row of $\overline{A}$ need only be computed against keys in its own cluster.
- Reformer (Kitaev et al., 2020) uses multi-round angular LSH with shared $Q = K$, restricting attention within hash buckets of bounded size.
- Routing Transformer (Roy et al., 2021) replaces LSH by mini-batch $k$-means clustering jointly on $Q$ and $K$.
- SMYRF (Daras et al., 2020) runs $H$ rounds of $k$-means clustering implemented via LSH to form balanced buckets.
- Multipole Attention (Hoorn et al., 2025) computes exact attention inside each cluster and approximates distant clusters by their centroid — a Fast Multipole Method analogue of attention.
Combined LSH and sampling.
- KDEFormer (Zandieh et al., 2023) relates softmax attention to a Gaussian Kernel Density Estimation problem and uses Approximate Matrix Multiplication with a sampling matrix $S$, giving $Y \approx \widetilde{Z}^{-1} A S^\top S V$.
- HyperAttention (Han et al., 2023) uses LSH to identify large entries of $QK^\top$ and leverage-score sampling for the rest.
Kernel-based sketches. If the softmax kernel is approximated by an explicit feature map $\phi: \mathbb{R}^{d_{QK}} \to \mathbb{R}^r$ with $\kappa(q, k) \approx \langle \phi(q), \phi(k) \rangle$, then $Z^{-1} A V \approx \Phi(Q)\bigl(\Phi(K)^\top V\bigr)$ and the cost drops to $\mathcal{O}(N r d)$.
- Skyformer (Chen et al., 2021) replaces the exponential kernel by a Gaussian $\kappa_{\mathrm{Gauss}}(x, y) = \exp(-\|x - y\|^2 / (2\sqrt{d_{\text{head}}}))$ and applies a Nyström approximation; the Gaussian normalisation makes the $Z^{-1}$ factor unnecessary.
- Performer (Choromanski et al., 2021) uses positive random features to give an unbiased approximation of the exponential kernel.
- PolySketchFormer and LevAttention use polynomial sketches and leverage-score sampling.
Low-rank projections. Some architectures bypass approximation altogether and simply define a low-rank attention.
- Linformer (Wang et al., 2020) projects $K$ and $V$ onto a fixed low-rank subspace of dimension $r \ll N$ before the softmax, making attention cost $\mathcal{O}(Nr)$.
- Nyströmformer (Xiong et al., 2021) applies a Nyström-like factorisation to the normalised attention matrix $\overline{A}$ itself, using landmark queries and keys obtained as segment-means.
- Loki (Singhania et al., 2024) compresses along the head dimension: it observes that $K$ has an effective rank far below $d_{\text{head}}$ and keeps only the top-$r$ principal components.
Tensor decompositions. When attention is extended to tensor inputs — images, multi-axis sequences — it naturally expresses as a higher-order tensor contraction. TEAFormer, Axial Attention, and Higher-Order Transformers replace dense $N^2$ attention by a sum of axis-aligned or tensor-train-factorised operators, trading expressivity for near-linear cost.
VIII. A Numerical Linear Algebra Reading
Once the veil of machine-learning vocabulary is lifted, the object of study is remarkably familiar to a numerical analyst.
The attention matrix $A$ is a dense, non-symmetric, entry-wise non-negative matrix whose row sums are enforced to 1. It admits, in practice, one of three structural regimes:
- Approximate sparsity — most entries are negligible after softmax, so $\overline{A}$ can be replaced by a sparse matrix with a controlled error (clustering, LSH, importance sampling).
- Approximate low rank — $\overline{A}$ is well-approximated by a matrix of rank $r \ll N$, and randomised SVD-style sketches suffice (Nyström, Linformer, Performer).
- Approximate tensor structure — when the input has tensorial regularity, $A$ inherits a Kronecker or tensor-train structure that classical dense methods cannot see.
These three regimes are exactly the menu that Randomised Numerical Linear Algebra (RNLA) has developed for generic dense matrices since the mid-2000s. The Transformer is, in this reading, a very large instance of RNLA applied to a data-dependent kernel matrix — with the added twist that the “matrix” is parameterised by learned weights and never explicitly materialised.
The consequence is twofold. Tools from RNLA — leverage scores, subspace embeddings, CUR decompositions, randomised range finders — are directly relevant to Transformer inference, and several (HyperAttention, KDEFormer, Skyformer) are already deployed. Conversely, Transformer workloads expose RNLA to regimes it has not traditionally optimised for: streaming data, autoregressive updates, attention sinks that break uniform-sparsity assumptions, and the strict autoregressive causality constraint that forbids access to future columns.
IX. Outlook
The contemporary landscape of efficient attention is no longer a handful of heuristics. It is an organised taxonomy:
- What structure does attention have? — sparse, low-rank, tensor, or several at once.
- Which numerical primitive exploits it? — importance sampling, Nyström, random features, tensor contractions.
- At what stage of training does the approximation live? — post-hoc at inference (HyperAttention), as an architectural prior (Linformer, Performer, MLA), or as a training-time sparsifier (Reformer, Routing).
Two open questions sit at the intersection of numerical analysis and machine learning. First, how to convert a pre-trained full-attention model into an approximate one with a provable quality guarantee — recent work on converting GQA/MHA into MLA (TransMLA) and on post-hoc LSH sketches points at a general answer. Second, whether the training process itself can be made to cooperate with the approximator, producing representations that are provably sparse or low-rank rather than only empirically so.
The Transformer is a mathematical object before it is an engineering one. Reading it through the lens of numerical linear algebra makes its costs legible, its approximations principled, and its remaining research questions sharp.
References
Primary sources.
- Serret, M. F. Understanding Transformers and Attention Mechanisms: An Introduction for Applied Mathematicians. arXiv:2604.00965, April 2026.
- Serret, M. F., Cortinovis, A., Dong, Y., Halikias, D., Ma, A., Matti, F., Needell, D., Pearce, K. J., Rebrova, E., Shur, D., Smith, R., Wang, H.-X., Grigori, L. Attention Mechanisms Through the Lens of Numerical Methods: Approximation Methods and Alternative Formulations. arXiv:2604.01757, April 2026.
Architectures.
- Vaswani, A. et al. Attention Is All You Need. NeurIPS, 2017.
- Ainslie, J. et al. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv:2305.13245, 2023.
- DeepSeek-AI. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv:2405.04434, 2024.
- Xiao, G. et al. Efficient Streaming Language Models with Attention Sinks. ICLR, 2024.
Approximate attention — clustering and sampling.
- Kitaev, N., Kaiser, Ł., Levskaya, A. Reformer: The Efficient Transformer. ICLR, 2020.
- Roy, A., Saffar, M., Vaswani, A., Grangier, D. Efficient Content-Based Sparse Attention with Routing Transformers. TACL, 2021.
- Daras, G. et al. SMYRF: Efficient Attention using Asymmetric Clustering. NeurIPS, 2020.
- Hoorn, T. et al. Multipole Attention, 2025.
- Zandieh, A. et al. KDEformer: Accelerating Transformers via Kernel Density Estimation. ICML, 2023.
- Han, I. et al. HyperAttention: Long-Context Attention in Near-Linear Time. arXiv:2310.05869, 2023.
Approximate attention — kernels and low-rank.
- Chen, Y. et al. Skyformer: Remove Softmax in Attention with Gaussian Kernel and Nyström Method. NeurIPS, 2021.
- Choromanski, K. et al. Rethinking Attention with Performers. ICLR, 2021.
- Wang, S. et al. Linformer: Self-Attention with Linear Complexity. arXiv:2006.04768, 2020.
- Xiong, Y. et al. Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention. AAAI, 2021.
- Singhania, P. et al. Loki: Low-Rank Keys for Efficient Sparse Attention, 2024.